text = c("Wealth, fame, power. Gold Roger, the King of the Pirates, attained",
"everything this world has to offer.")
text[1] "Wealth, fame, power. Gold Roger, the King of the Pirates, attained"
[2] "everything this world has to offer." Alexander Fisher
Duke University
A regular expression (aka regex or regexp) is a custom defined string matching pattern. A regular expression lets you:
extract only the phone number from this string: “My phone number is (123) 456-7890, not to be confused with my birth month which is 0”
search and replace multiple spellings of the word gray (grey, 6R3Y) in a document simultaneously
search through all files in a directory for the one that contains a specific string
find the specific line number from a file that contains a string
find and replace through multiple files simultaneously
And much, much more!
grep and grepl are base R functions that return the index of a match and the logical value of a match respectively.
stringr hosts a convenient set of tools to manipulate strings and extract regular expressions. All functions begin with the prefix str.
The best summary of stringr functions is on this cheatsheet
Notice below that the string comes first in these functions (in contrast with grep)
str_replaceTo match a string exactly, just write those characters.
To match a single character from a set of possibilities, use square brackets, e.g. [0123456789] matches any digit.
To group characters together into an expression, use parentheses, ()
Repeaters: * , + and { }: the preceding character is to be used for more than once
* match zero or more occurrences of the preceding expression.
+ match one or more occurrences of the preceding expression.
{} match the preceding expression for as many times as the value inside this bracket.
Some repeater examples:
| regexp | explanation |
|---|---|
a* |
match 0 or more occurences of “a” |
a+ |
match 1 more occurences of “a” |
(abc)+ |
match 1 or more back-to-back occurence of the group “abc” |
a{3} |
match a 3 times |
a{3,} |
match a 3 or more times |
a{3,5} |
match “a” 3, 4 or 5 times |
{citation: https://www.geeksforgeeks.org/write-regular-expressions/}
. symbol for wildcard. The dot symbol can take place of any other symbol.
? symbol for optional character. The preceding character may or may not be present in the string to be matched. Example: docx? will match both docx and doc
$ symbol for position match end. Tells the computer that the match must occur at the end of the string or before \n at the end of the line or string.
\ symbol for escaping characters. If you want to match for the actual + or ., etc. add a backslash \ before that character.
| symbol for “or”. Match any one element separated by the vertical bar | character. Example: th(e|is|at) will match words “the”, “this” and “that”.
^ symbol has two meanings.
By itself, ^ sets the position of the match to the beginning of the string or line. Example: ^\d{3} says to match the first three digits at the beginning of the string and will return 919 from 919-123-4567.
Together with brackets, [^set_of_characters] implies exclusion. Example: [^abc] will match any character except a, b, c.
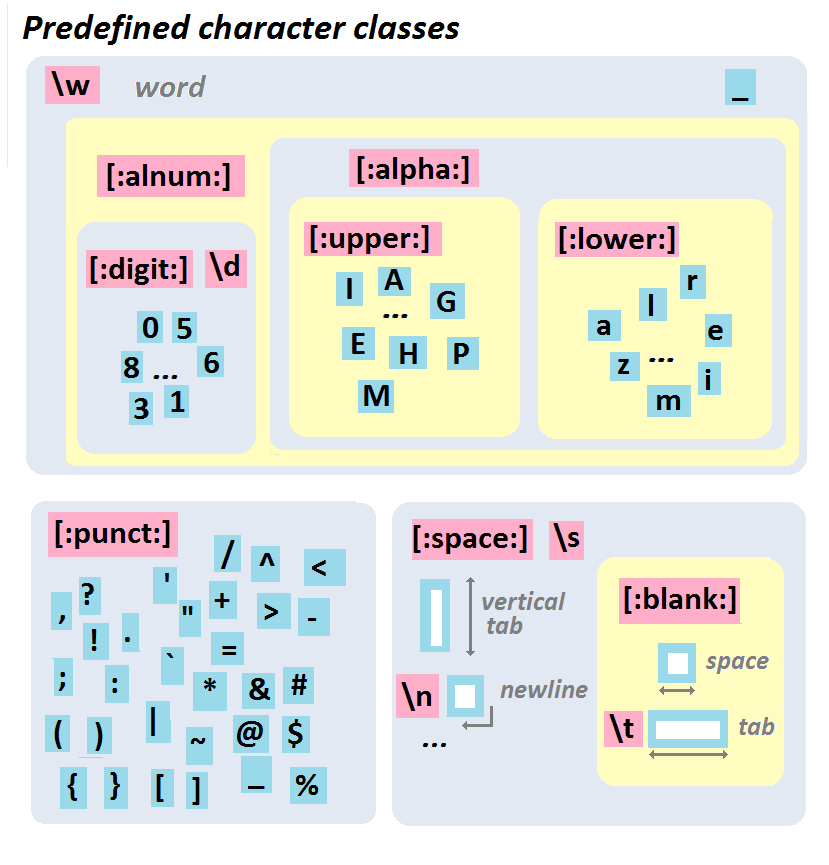
Character classes: match a character by its class, for example: letter, digit, space, and symbols.
\s : matches any whitespace characters such as space and tab
\S : matches any non-whitespace characters
\d : matches any digit character
\D : matches any non-digit characters
\w : matches any word character (basically alpha-numeric)
\W : matches any non-word character
\b : matches any word boundary (this would include spaces, dashes, commas, semi-colons, etc)
{citation: https://www.geeksforgeeks.org/write-regular-expressions/}
{citation: http://perso.ens-lyon.fr/lise.vaudor/strings-et-expressions-regulieres/}
- can be used to interpolate between first and last and grab consecutive values. Example: [A-Z] matches any capital letters from “A” to “Z”. [1-4] matches any integer digit from 1 to 4.
To match an alphabetical character (upper or lower case “A-Z” or “a-z”) but not numbers, you can use the regular expression ([A-Z]|[a-z])
To match everything but capital “F” through “N”, you can use the regular expression [^F-N]
When to escape?
. ^ $ * + ? { } [ ] \ | ( )Are all special and perform as described on the previous slides by default. Therefore, these special characters must be escaped to match directly. You need to use two levels of escape to escape a special character. Example:
Error in stri_detect_regex(string, pattern, negate = negate, opts_regex = opts(pattern)): Missing closing bracket on a bracket expression. (U_REGEX_MISSING_CLOSE_BRACKET, context=`[`)In order to access the presumed functionality of character classes, you need to use a double escape as well. Example:
tl;dr
to match a symbol or character class, use double escapes
Download the files secret-message.txt and emails.txt using the command below in the console:
WARNING
DO NOT VIEW THE FILE – YOUR CONTAINER MAY CRASH!
Hint: read in the file as a string with read_lines()
In secret-message.txt, find the secret message. It will be of the form DataFest{secret-message} where secret-message is replaced by some other text.
In emails.txt extract the unique part of the email address (part before the “@”) and count the number of each hosting domain, i.e. count how many emails are Duke emails and how many are gmail.
In the following example we will search through the text and extract matches.
What went wrong here?
If you add ? after a repeater, the matching will be non-greedy (find the shortest possible match, not the longest).